Welcome
What is Nebuly?
Welcome
What is Nebuly?
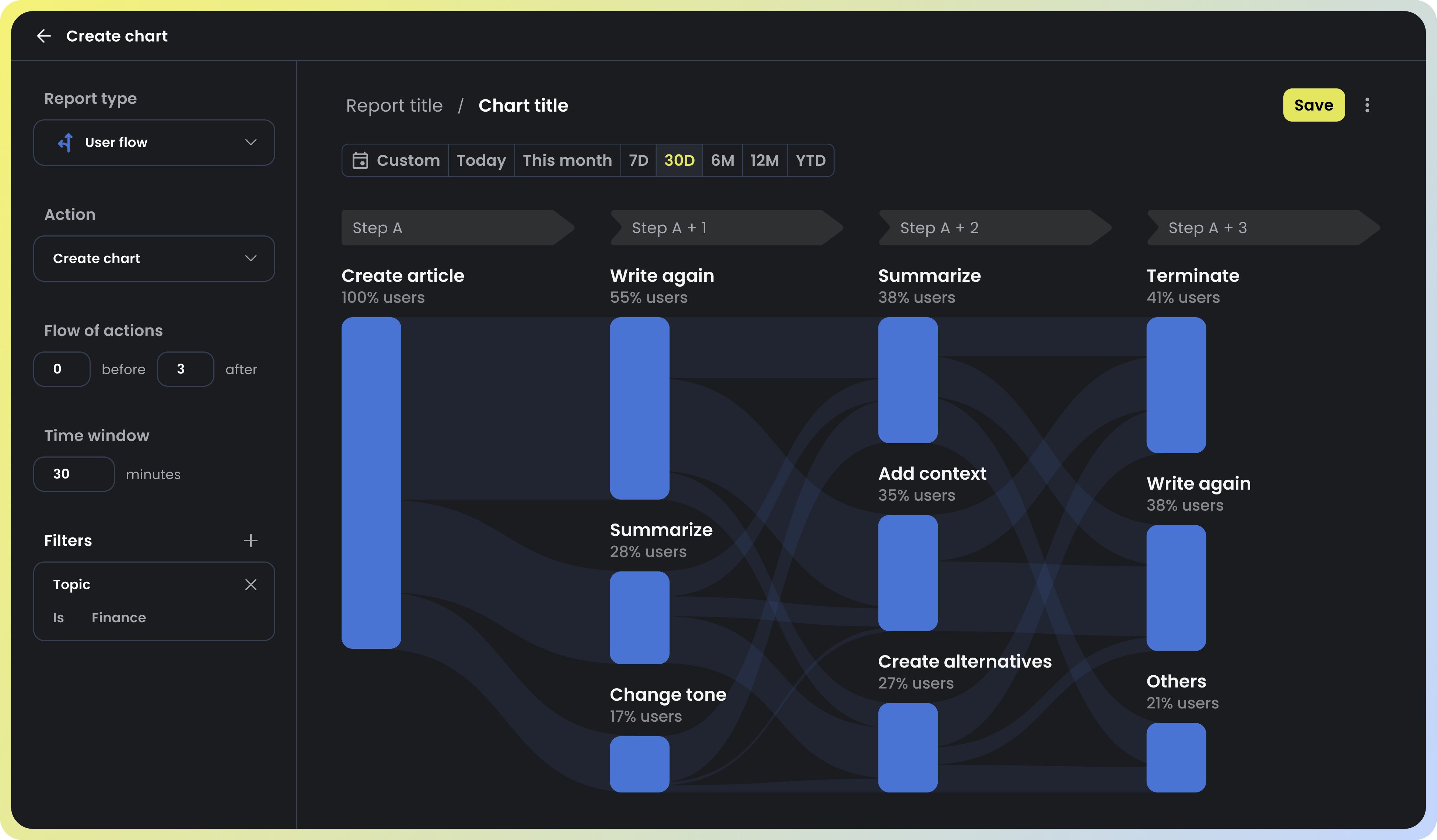
Nebuly is the user analytics platform for LLMs enabling you to automatically capture how your users interact with your models. The platform helps you understand what your LLM users like, what they don’t and why, what are the most asked questions and how you can improve your LLMs products to delight your customers.
Our platform empowers your team to have instant clarity into massive LLM user data.